Purpose
This experiment is the primary evidence for the deep-scaling claim. It trains MLP, ResidualMLP, and SymplecticPINN architectures at depths 4, 10, 25, and 50 on the 1D heat equation under a matched parameter budget.
Gradient shattering — the progressive compression of useful gradient signal with depth — is identified by Abijuru et al.[5] as one of the two primary failure modes of deep PINNs. Their ResPINNs reformulate the network as a residual flow to preserve gradient signal; our approach achieves the same end through geometric structure: each Störmer-Verlet layer is an exact symplectic map, meaning the gradient-path volume is conserved layer-by-layer by construction rather than through architectural correction.
The test measures two quantities:
- The Jacobian singular-value spectrum of the trunk before and after training.
- The final training loss at each depth.
Jacobian spectrum at initialisation
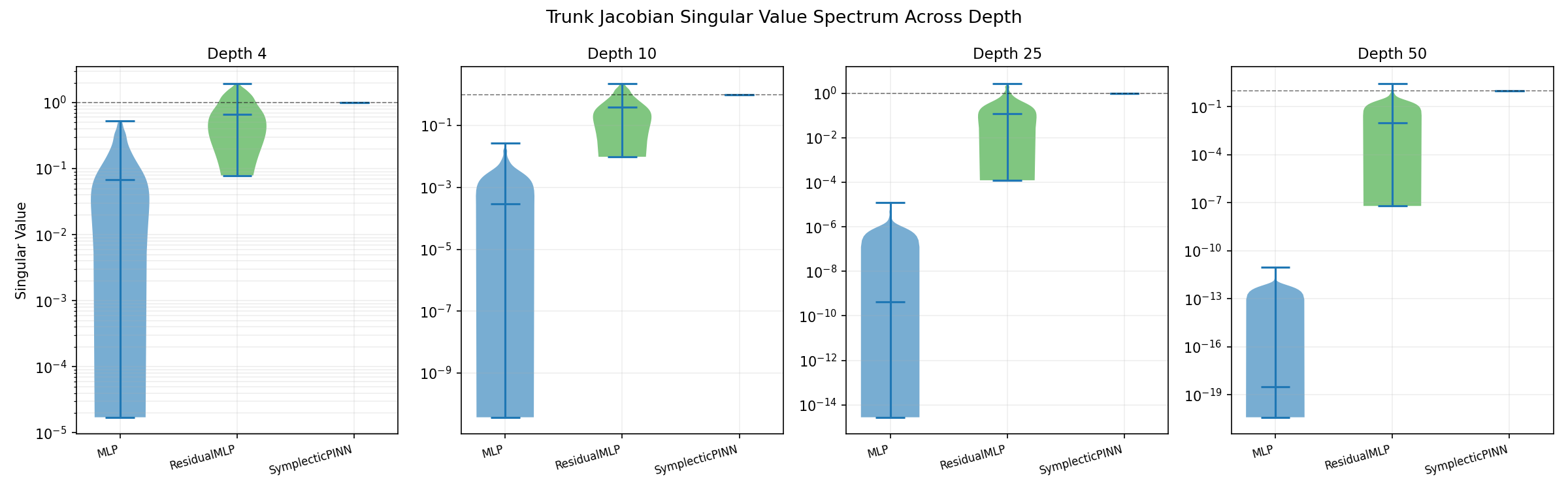
The MLP shows severe singular-value collapse before training. By depth 10, the singular values span many orders of magnitude, and by depth 50 the gradient path is effectively broken. ResidualMLP improves this behavior but still shows a broad spectrum. SymplecticPINN keeps singular values tightly clustered near 1 across all tested depths.
The structural explanation is rooted in Hamiltonian geometry. Aich and Aich[1] prove that any architecture built from a separable Hamiltonian — kinetic energy T(p) plus potential energy V(q) — defines an exact volume-preserving map. Volume preservation in phase space is equivalent to bounded singular values: the map cannot collapse or expand phase-space volume, so its Jacobian must have determinant 1, preventing both vanishing and explosion of gradient signal before a single parameter update has been made.
Jacobian spectrum after training
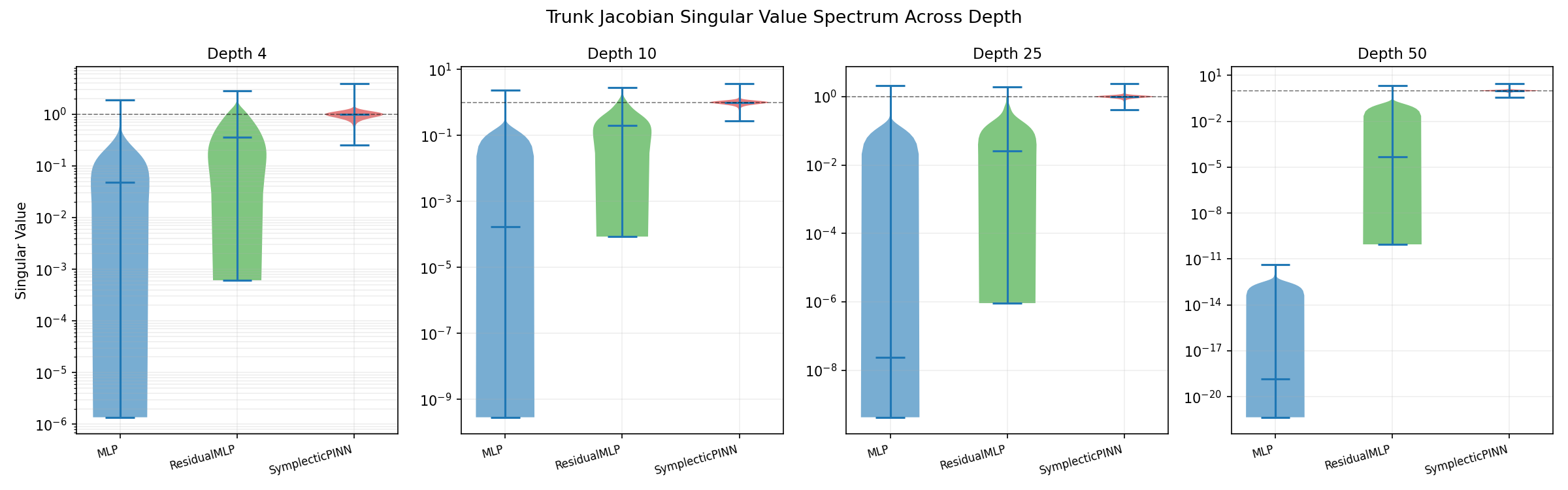
After training, the MLP remains collapsed and can become worse. ResidualMLP remains similar to its initialization behavior. SymplecticPINN keeps a narrow spectrum, showing that training does not destroy the structural property — the Störmer-Verlet updates preserve the symplectic form at every step.
Canizares et al.[2] demonstrate a complementary result for learned Hamiltonian systems: symplectic neural flows preserve energy conservation through training even for chaotic and dissipative systems, with backward error analysis guaranteeing proximity to an exact Hamiltonian flow. In our experiments the conserved quantity is gradient-path volume — the property that makes deep training tractable — and Störmer-Verlet integration preserves it by construction at every layer.
Depth-50 comparison
At depth 50, the comparison is clearest. The MLP has lost meaningful gradient directions. ResidualMLP remains trainable but lacks a tight spectrum. SymplecticPINN retains healthy singular values, which supports the central gradient-flow argument.
Tanaka et al.[3] formalize this geometric perspective using Symplectic Spectrum Gaussian Processes, demonstrating that a prior over the symplectic group acts as a structural regularizer keeping dynamics well-conditioned under noisy observations. Our empirical result — the minimum singular value remaining above 0.25 at depth 50 — is the finite-network analogue of their theoretical spectral bound.
Training loss versus depth
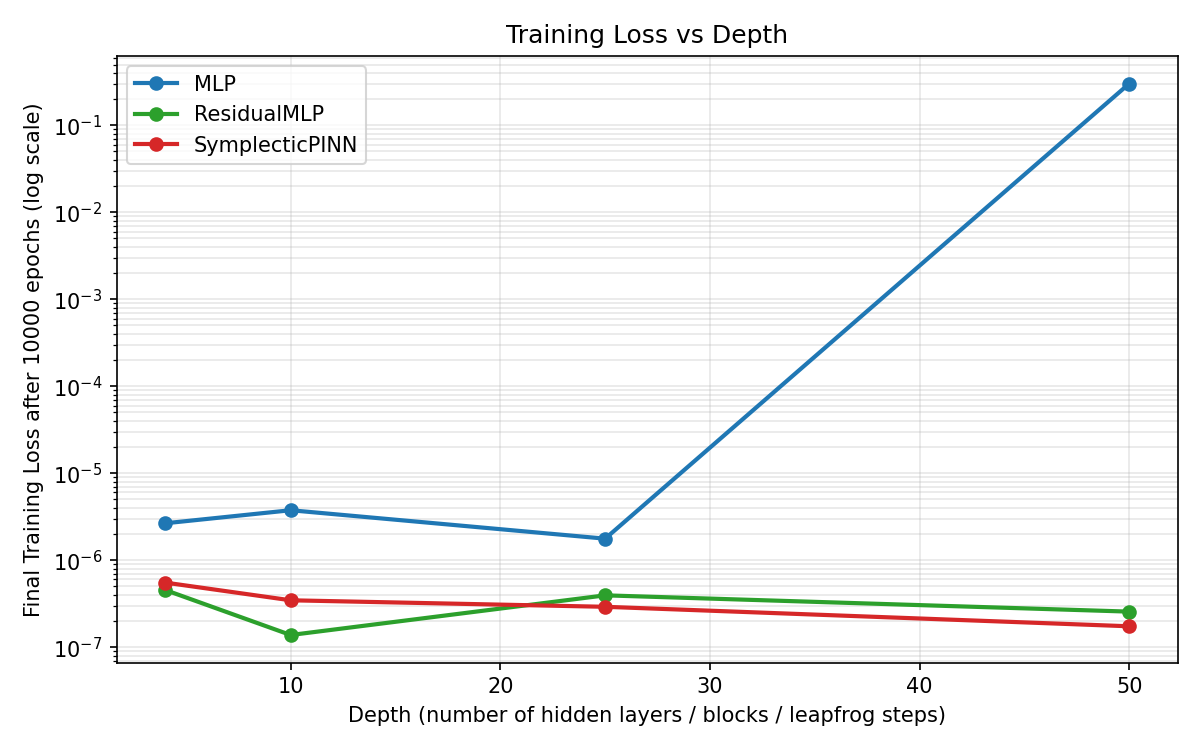
The MLP is roughly stable up to depth 25 but fails catastrophically at depth 50, with loss increasing by several orders of magnitude. ResidualMLP stays stable. SymplecticPINN also stays stable and improves slightly as depth increases, suggesting that the optimizer can use the extra capacity when gradient flow is preserved. This contrasts with the Greydanus et al.[4] setting, where depth was not a primary variable — their Hamiltonian constraint was applied to a shallow energy network. The present experiment shows the constraint remains effective at depths that break standard residual architectures.
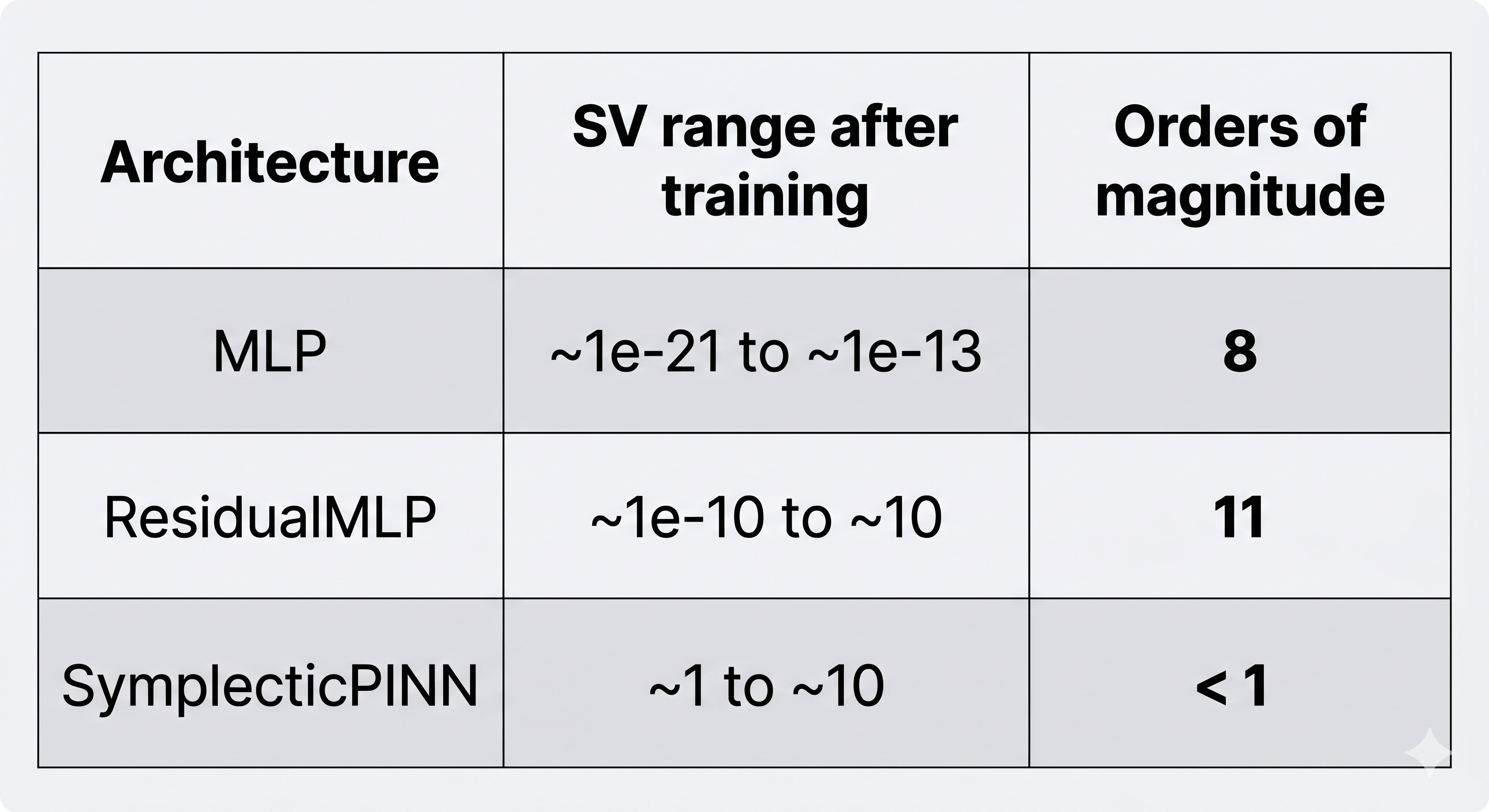
Numerical summary
The minimum singular value is the most important diagnostic. A value near zero means at least one latent direction receives no useful gradient signal. The notes report that MLP reaches numerical zero at every depth, ResidualMLP delays but does not prevent collapse, and SymplecticPINN keeps the minimum singular value above approximately 0.25. This is the quantitative evidence for the claim that Störmer-Verlet integration preserves gradient signal across all tested depths.
Caveat: these plots should be regenerated from the final corrected separable-Hamiltonian architecture before paper submission. The qualitative finding is expected to hold, but reproducibility should come from committed final code.
References
- (2025). Symplectic Generative Networks: A Hamiltonian Framework for Invertible Deep Generative Modeling. arXiv:2505.22527. ↗
- (2024). Symplectic Neural Flows for Modeling and Discovery. arXiv:2412.16787. ↗
- (2022). Symplectic Spectrum Gaussian Processes: Learning Hamiltonians from Noisy and Sparse Data. Advances in Neural Information Processing Systems 35 (NeurIPS 2022). ↗
- (2019). Hamiltonian Neural Networks. Advances in Neural Information Processing Systems 32 (NeurIPS 2019). ↗
- (2025). Physics-Informed Residual Flows. EurIPS 2025 Workshop on Differentiable Systems (DiffSys). ↗